
Platform
Use Cases
ACCOUNT SECURITY
Account TakeoverMulti-AccountingAccount SharingIDENTITY & FRAUD
Synthetic IdentitiesIncentive AbuseTransaction FraudPricing
Docs
January 28, 2019
We recently told the story of our first general outage at hCaptcha.
This was caused by an outage at the Argo Tunnel service provided by Cloudflare, a vendor we use for traffic routing and DDoS prevention.
Unfortunately, we had assessed the likelihood of a sustained Cloudflare outage as low enough that no automated system was initially in place. This caused several minutes of downtime as our on-call staff manually rerouted traffic upon being paged on January 24th.
Less than 24 hours later it happened again:
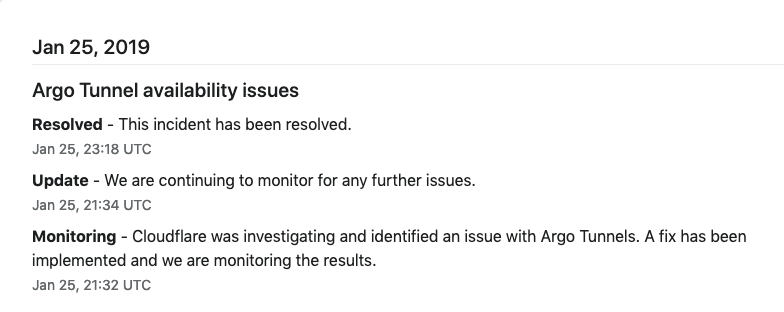
And then again on January 28th.
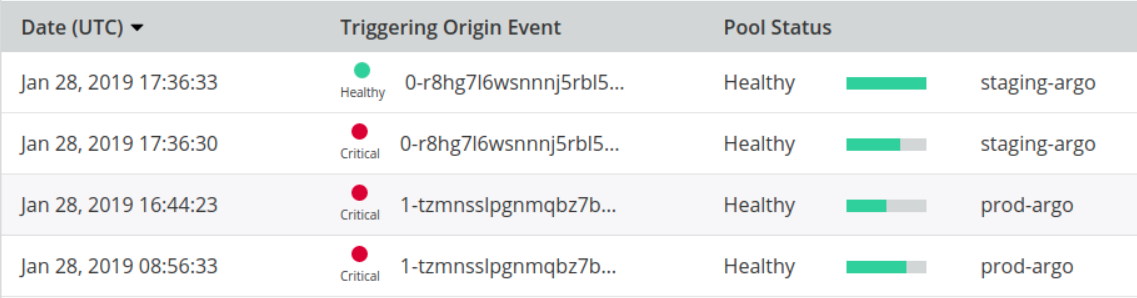
This time we were prepared: neither outage was visible to our users.
We started work on fully redundant traffic routing and DDoS prevention to completely route around single provider issues after the first incident, but realized another solution existed for the short term.
As an interim measure to safeguard our users we changed our routing topology for inbound traffic. It initially followed the path:
[user]->[internet]->[Cloudflare]->[CF Argo Tunnel]->[hCaptcha Kubernetes clusters]
After deciding Argo might continue to be a point of failure, we inserted a load balancer within Cloudflare ahead of it:
[user]->[internet]->[Cloudflare]->[CF LB]->[CF Argo Tunnel]->[hCaptcha Kubernetes clusters]
The alternate route then went directly to each cluster ingress:
[user]->[internet]->[Cloudflare]->[CF LB]->[hCaptcha per-cluster ingress]->[hCaptcha Kubernetes clusters]
This strategy was immediately tested. Argo suffered service issues on January 25th and January 28th, but our users were unaffected. Failover was seamless and immediate.
We hope this glimpse of how we approach site reliability engineering here at hCaptcha serves as a helpful note for those affected by similar issues.
Postscript: We are currently implementing a fully redundant traffic routing and DDoS prevention system. External health checks will automate rapid failover to another vendor in the event that Cloudflare suffers intermittent or continuous downtime in the future.
We plan to open source our implementation of this failover functionality, which is being built on top of our current multi-cluster Kubernetes operations. If you are interested in getting early access or collaborating, send us an email at support@hcaptcha.com and we’ll let you know before the repo goes public.
PPS: The Cloudflare Argo product team reached out to us after these incidents to explain how they happened and what steps they are taking to prevent reoccurrences in the future.
We appreciate their transparency, and believe they will prioritize reliability going forward. We are continuing to use both Cloudflare and the Argo service (with additional safeguards) for now and will report on any future issues.
— Eli, Alex, and the hCaptcha infrastructure team















