
Platform
Use Cases
ACCOUNT SECURITY
Account TakeoverMulti-AccountingAccount SharingIDENTITY & FRAUD
Synthetic IdentitiesIncentive AbuseTransaction FraudPricing
Docs
August 27, 2018
2023 Update: This post was originally written in 2018, and the system has evolved as hCaptcha has scaled to serve hundreds of millions of people and more use cases. We have lightly revised it, but it is mainly of historical interest.
This post details how hCaptcha works on a technical level, in the interest of providing more transparency to our users and to communicate our thinking on how to build a secure and valuable service.
Note: hCaptcha is under active development and details may change in the future.
The hCaptcha service provides a useful service to website owners by protecting their sites from fraud and abuse, especially non-human actors and bots.
Everyone benefits from this:
The basic interaction flow is as follows:
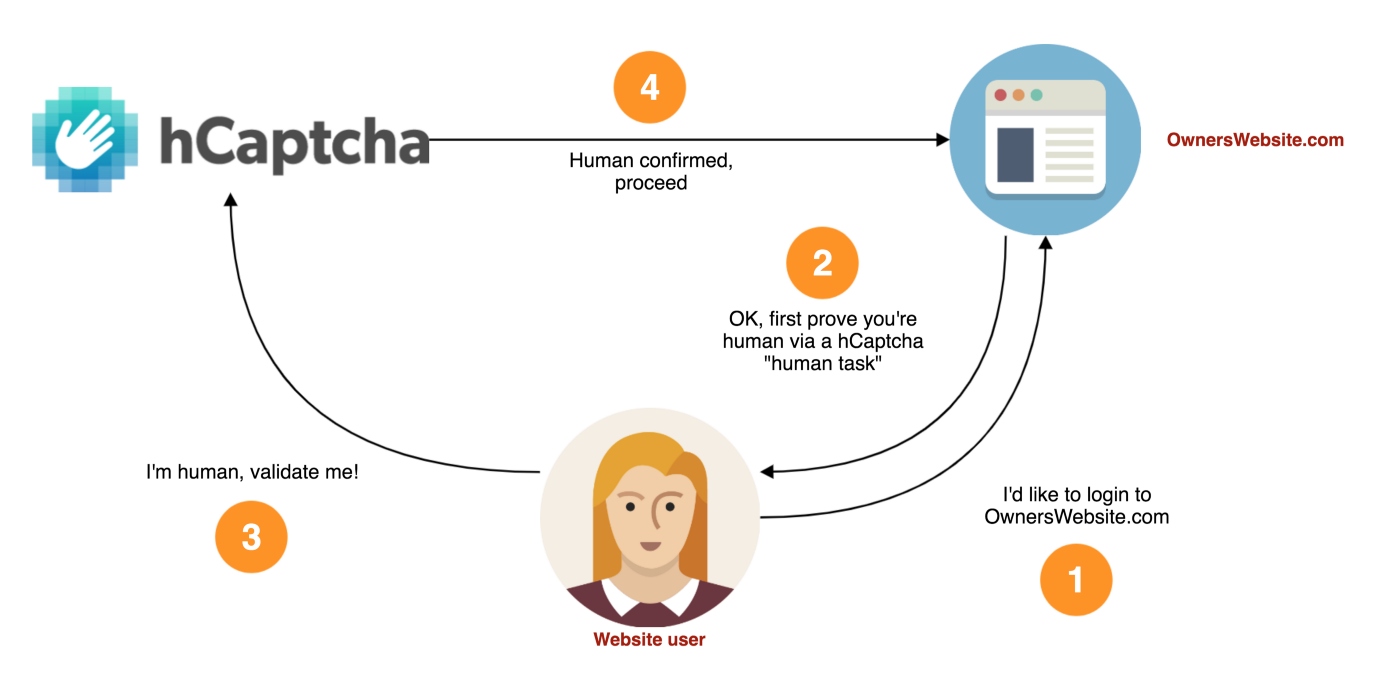
For website owners, the process to get involved is incredibly simple and is built to be a drop-in replacement for existing captcha services out there. Simply sign up and add our JavaScript tags where you want to protect your site. It’s as easy as that.
A common question that arises is: “how does hCaptcha know the answers to user-submitted, generic tasks if a human has never been involved?”
The answer is by combining many different techniques:















