
Platform
Use Cases
ACCOUNT SECURITY
Account TakeoverMulti-AccountingAccount SharingIDENTITY & FRAUD
Synthetic IdentitiesIncentive AbuseTransaction FraudPricing
Docs
June 7, 2023
Public awareness of generative AI's abuse potential is increasing, and a number of products now claim to offer LLM output detection through text analysis. Having worked on these topics for many years, we have found that naive approaches to this problem are extremely unreliable.
To see how these new entrants stack up, we used data from our recent report Generative AI is making some platforms useless to test popular detectors on confirmed LLM and human output we captured in the wild.
No public AI text detector we tested scored better than random chance. Results were very unstable, with small changes to input text flipping detections in both directions. LLMs also failed to reliably detect LLM output in our tests.
Members of the public should not rely on freely available services for AI text detection.
To test the reliability of AI text detection tools, we ran popular detectors against the validated text samples from our recent "in the wild" LLM detection research.
First, we chose popular AI text detectors by picking the top five search results:

For each detector, we ran LLM, mixed, and human samples through it and recorded the results.
To further evaluate each detector's stability of detection, we tried several variants on the inputs to see if spacing, newlines, or input length reduction materially changed their output.
We tested 5 public detectors plus ours on 18 in-the-wild text samples, each with 3 variations: the original and two versions with small changes made in order to test the stability of their detection.
324 data points were evaluated in total. This included paired LLM and human text samples from the same person, adding an adversarial dimension not found in most benchmark datasets.
Table 1 covers only results on unaltered text. However, our stability analysis found that each public detector was highly unstable: removing the last complete sentence or the last 100 characters of a text sample often completely flipped their detection results or greatly reduced their reported class confidence score.
Table 1.
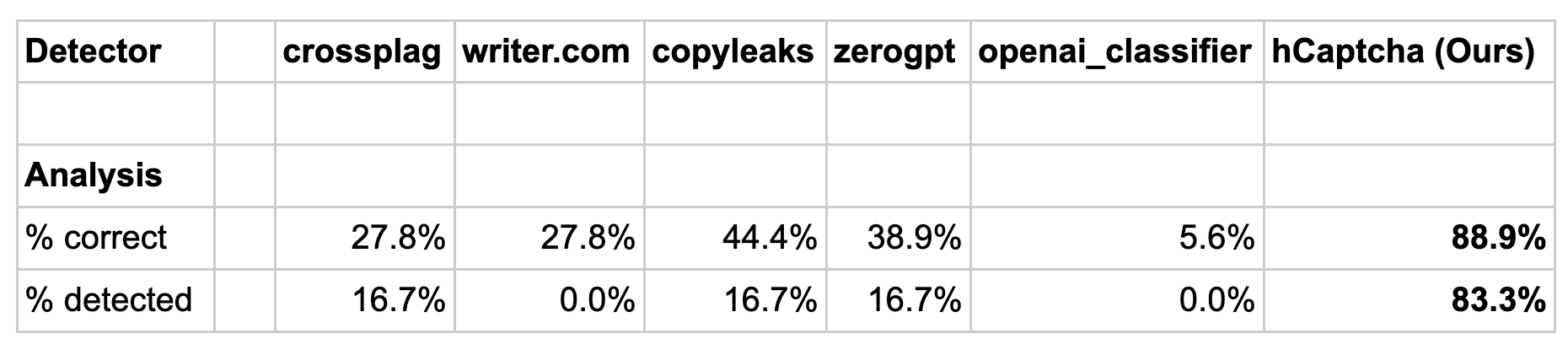
When tested on LLM and mixed samples, no public detector scores better than 16.7% detection accuracy.
In other words, they classify most (but not all) human text as human, and fail to classify almost all LLM text as AI generated.
The repeating 16.7% accuracy is due to three public detectors agreeing on one clearly non-human sample text, and each identifying one other LLM sample (different in each case) that happened to be correct. A larger dataset would likely show even lower detection accuracy.
While our research detector is more accurate, it is not designed for online analysis, and is below our accuracy targets for stand-alone ML products we make available to the public. This means it is primarily useful within an ensemble of other signals at the moment. However, we continue our work in this area, and have identified some avenues for potential improvements.
Analysis notes:
1. The calculation above uses the most generous interpretation of correct, treating both "is LLM" and "is mixed" as correct when the correct detection was either answer.
In other words, if the right answer was "is mixed" and the detector reported "is LLM" or if the answer was "is LLM" and the detector reported "is mixed" then these cases were both counted as a detection for the "% detected" row.
2. OpenAI's classifier requires 1500 characters to provide a result, but many samples were in the 1000-1500 character range. This meant it returned no result on 39% of the dataset.
Given its poor performance on the 61% of samples greater than 1500 characters, our judgment is that it would be unlikely to do materially better on a similar corpus with more samples in the 1500-2000 character range. It failed to detect any LLM samples, including those we determined were produced via ChatGPT.
3. Inter-model agreement was generally low on LLM samples, with the exception of a single true positive datapoint that 4/6 models agreed on. Only OpenAI and writer.com failed on this sample.
We used a standard zero shot prompt:
Is the following text A) generated by a human, B) mixed text from a human with some LLM output, or C) entirely LLM output? Please answer A, B, or C along with a confidence score of 0-1, where 0 is no confidence and 1 is 100% confidence.
TEXT:
and tested the two best-known LLMs, Anthropic's Claude and ChatGPT (May 24 version).
This exercise confirmed our prior findings that popular LLMs are not good text classifiers, and have no special skill at LLM sample detection out of the box.
As would be expected from next-token predictors prompted with the concept of human vs. LLM authorship, their bias is shifted more towards predicting B or C.
Raw answers from the Claude LLM for a 100% LLM sample are below. This was produced from the same input, with the answer regenerated 5 times.
A, 0.7
C, 0.7 confidence
B, 0.6
C, 1
B, 0.6
And ChatGPT:
A) generated by a human. Confidence score: 0.95
B) mixed text from a human with some LLM output. Confidence score: 0.8
B) mixed text from a human with some LLM output. Confidence score: 0.8
A) generated by a human. Confidence score: 0.9
B) mixed text from a human with some LLM output. Confidence score: 0.9
Claude performed at around the rate of random chance over 20 retries. ChatGPT underperformed random chance, never picking C in 20 retries.
Their confidence scores were consistently high even though answers changed on most retries.
We hope this demonstration illustrates that you should not blindly trust output of a next-token predictor, especially one with a "temperature" set to the high defaults of OpenAI and Anthropic. This makes its output very unstable.
We chose the prompt above as something that the average person might plausibly use.
"Prompt engineers" may object that a more sophisticated prompt would produce better results. However, this is only true when the model has some skill in the underlying task.
Nonetheless, using the highest ranked results from recent prompting papers we modified the prompt above by appending the following sentences prior to TEXT:
"Let’s work this out in a step by step way to be sure we have the right answer. Show your work, explain your reasoning, and go step-by-step to produce a final answer and confidence calculation."
This caused both Claude and ChatGPT to produce superficially plausible reasoning. However, their answers were equally inaccurate, with a continued bias towards picking B or C on both 100% LLM and 100% human text.
These approaches are outside the scope of a report on publicly available detectors likely to be used by the general public. However, we will briefly note they are highly vulnerable to dataset and prompt input bias, and can easily mislead researchers in skill tests.
Reliable LLM detection via passive textual analysis alone is difficult. All well-known options were extremely unreliable in our experiments. This has the potential to create real world harm if members of the public believe these systems are accurate and rely on their results.
New entrants using simple classifier strategies will struggle to deliver anything useful here, and false positives have a high penalty in these systems. You may have seen news stories recently about a teacher who flunked nearly his entire class based on his mistaken application of ChatGPT to LLM detection. We expect more examples of this sort.
Generative AI will bring advantages as it filters out into the world, but reliable detection of automated interactions is increasingly important. Online services are not yet prepared to mitigate the inevitable abuse of this new technology, so critical thinking and skepticism is more valuable than ever as we engage with content both online and offline.
There is also an enormous amount of confusion in the popular understanding of LLMs, how they work, and what their outputs mean. We hope these demonstrations of their task performance in two domains and the effect of temperature on LLM outputs help non-specialists to develop a more intuitive understanding of their limitations.
hCaptcha Enterprise stops the most sophisticated automated attacks. We'd be happy to help.
An integrated fraud and abuse solution like hCaptcha Enterprise is the most reliable way to find and stop abuse, including LLM-mediated automation. We expect this kind of abuse will further spread across many kinds of online services this year.
Was the conclusion of this report obvious to you? Check out our open jobs.
Based on our black-box analysis of detector outputs and the public remarks of their creators, it appears that these detectors generally use simple binary classification models, e.g. naive Bayesian or SVM approaches, and train on some limited number of samples in each class.
This is not a winning strategy for LLM detection. As we demonstrated in this report, simple models struggle to discriminate between human and LLM output.
Most likely their training datasets did not contain a wide variety of source material, and thus they had no chance to accurately distinguish between classes when samples slightly deviated from their training sets.
hCaptcha's research in generative AI has led us in a completely different direction for detection. The approach we validated on these in-the-wild samples is more resource-intensive than a simple Bayesian classifier, but also appears to be more robust.
This experiment had a small sample size and focused on only two kinds of communication formats, so follow-on research is warranted to confirm and elaborate on these results.
However, a small number of real in-the-wild samples is often more indicative than a large number of less relevant samples when measuring real-world performance. We have not yet seen a high quality public benchmark dataset that includes matched pairs and naturally adversarial samples like the ones found in this dataset.
The intrinsic difficulty of maintaining detection capabilities like these also creates a strong disincentive to releasing such a dataset. It would likely be scraped for inclusion in future LLM training datasets, and abused by bad actors.
However, we have included an example message pair in Appendix B for purposes of illustration.
Note: we received permission to reproduce both the conversation and anonymized portions of their bid text.
Hi,
I am sending you a message because I came across your job post for anomaly detection with ClickHouse and it has piqued my interest.
<Standard intro deleted>
During my career, I have worked with dozens of blue-chip level enterprises as well as small and medium-sized businesses, across a wide range of industries and in <Number> countries all over the world. I have worked on multiple projects involving ClickHouse and anomaly detection.
Here are a few successful deliveries that fit your requirement:
- Customer Churn Analysis for a Telecom Company
- Challenge: The telecommunications company was experiencing a high rate of customer churn and needed to identify their most problematic areas to improve customer retention.
- Solution: I analyzed their customer data and provided a custom ClickHouse solution that detect the anomalies as soon as they emerged.
- Results: The implemented solution reduced churn rate by 40%.
- Fraud Detection for an E-commerce
- Challenge: The e-commerce platform faced high order cancellations due to fraud transactions.
- Solution: I proposed a ClickHouse-based real-time anomaly detection system to detect fraudulent transactions using <suggested algorithm> for running variance analysis.
- Results: The implementation successfully detected more than 90% of fraudulent transactions and reduced word cancellation rate by 60%.
<More standard copy deleted>
Regardless of us ultimately working together, I take pride in always leaving prospects like yourself with valuable insights that you can apply directly and help you move forward.
Specifically, I'll provide you with:
- Best practices for real-time anomaly detection using ClickHouse
- Specific recommendations on implementing <suggested algorithm> for running variance analysis
Did you notice anything there? If you read our previous report, this seems like awfully germane prior expertise!
This nearly verbatim rephrasing of the prompt was obvious LLM fiction to us, but non-specialists could certainly be misled.
To confirm the analysis, we followed up:
Us: Looks like you used an LLM to write this.
Them: Hi, many apologies for subjecting yourself to that.
As an AI first org, we are currently experimenting with leveraging the technology across all operations, incl. outreach, however: for strictly mutually beneficial purposes. While the information in the propsoal is 100% accurate, it should have never been sent live, hence it was so utterly uncalibrated and unrelated to your job post. (And pretty poor overall, I should add).
Again, genuinely sorry!
I wish you best of luck and success with your project,
Have a great weekend
Us: Seems risky. Probably all of the relevant information there is hallucinated ("Solution: I proposed a ClickHouse-based real-time anomaly detection system to detect fraudulent transactions using <suggested> algorithm for running variance analysis.") so you will end up bidding on work you may not be qualified for.
Them: 100%. We're trying to see if and to which extent we can make it adhere to strict guidelines via through smart prompting and other mitigation measures. I am personally very keen about experimenting and get a lot of personal satisfaction from it, especially these days. Just need to stop doing so late at night, when it's indeed very risky (in that case, a flag for "test mode" not being set). Again, apologies, it never was designed to be sent, we are far from there (if we ever get there).















